Automated Simulation Management and Reproducible Research
My wife was delighted when I gave her a Fitbit as a holiday gift. An unfortunate consequence of her continued enthusiasm is that we often end up heading out on a cold winter’s night to the local grocery store, where we power walk up and down the aisles until she reaches the magic 10,000 steps – indicating that she has exercised enough to satisfy the Fitbit gods. Aside from the small inconvenience of having to rush around Wegman’s late at night as the staff there give us perplexed looks, the Fitbit is a wonderful device. It records the number of steps taken each day, one’s weight (with the purchase of the accessory, somewhat pricey, scales), sleep, vertical steps and more. The results are stored in the cloud and presented on a website with upbeat graphics that render the data easily digestible.
Considering the technology available for data capture in our daily lives, the scientific process seems increasingly moribund in comparison. My everyday workflow often consists of running multiple numerical simulations across different research projects. Up until recently, I kept records of these simulations using mostly manual and entirely ad hoc schemes. Intuitively, one would imagine that maintaining simulation records for computational processes would be a relatively straightforward problem. After all, this is a deterministic process existing entirely in silico and is seemingly much simpler than capturing in vivo/vitro data as with the Fitbit or an experimental apparatus. In practice, I find that managing numerical simulations and the associated output data is a maintenance nightmare mainly because I tend to alter the ad hoc management schemes frequently. This results in rapid degradation of data, especially after the conclusion of a research project.
I am mystified as to why there are not at least a half-dozen well supported, open source projects that address the issues surrounding simulation management. Web frameworks that support cloud storage, sharing and versioning of simulation metadata should be commonplace. I can say with some conviction that scientists have sleepwalked through the last 10 years of web technology development. It is high time that we step away from the research and concentrate on building the tools and web infrastructure needed to improve the scientific process, especially in the realm of scientific computing.
Workflow, Version Control and Event Control
I think it is important to be clear at this point that I do not advocate for an all encompassing workflow tool that presumes to manage every aspect of one’s scientific life, but really just a tool to deal with event control. Event control is very different from version control or workflow. Event control is the versioning and capture of metadata associated with the execution of a workflow (or just a script or computer program) while version control records the changes in a workflow. Event control shares many similarities with version control, but records different types of metadata at each commit (or execution). Git is a simple, robust command line tool for version control. It forms a platform for many other high level tools and web services (e.g. Github). In my mind, to implement web infrastructure and fancy cloud services for data provenance, a tool along the same lines as Git is required for event control.
Data and Metadata
An important issue to be aware of is the distinction between output data produced by simulations and metadata about simulations. The arguments in this blog post are mostly related to the latter. The provenance of metadata is, in principle, a much easier problem to deal with than the provenance issues surrounding the vast quantities of data produced by simulations. The size of the metadata is almost inconsequential in comparison to the simulation output data and it is also much easier to develop simple protocols and standards for metadata capture. I acknowledge that provenance issues surrounding simulation output data are hugely important, but the output data issue can not be tackled effectively until the metadata issue is adequately resolved.
Reproducible Research
The following figure is an idealized schematic showing the five stages of progress during a computational research project.
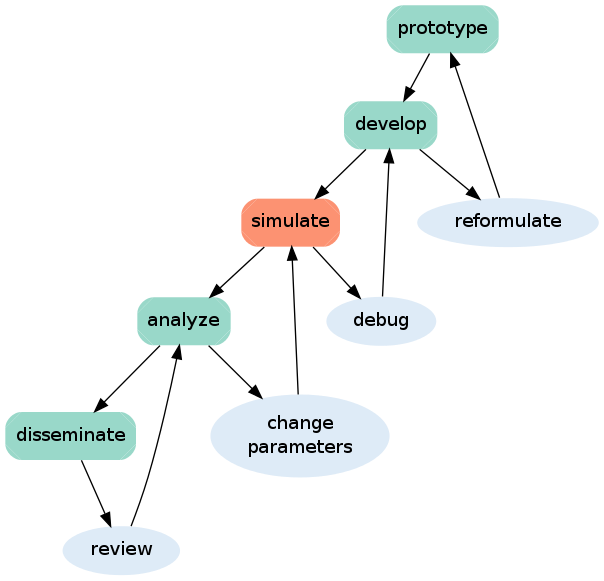
As a general rule, it is easier to reproduce the final two stages of this process than the first three assuming the simulation output data is readily available. The use of version control may help with general workflow and aid reproduction during all of these stages, but it is most useful during the development stage. Presumably it is difficult to capture much provenance data at all during the prototyping and development stages. Moreover, there is no real need for these stages to be formally reproducible. In my opinion, the simulation stage is where current practices really need to be improved. This after all is the most important part of any project with respect to reproducible research. It forms the backbone of a research project, it is analogous to the execution of an experiment as opposed to the assembling of the apparatus or rendering of a figure in a laboratory notebook. Ideally, the simulation stage of a project is a mode of working that has a well defined workflow. It uses a well developed code base and mostly involves changing input parameters (and maybe only tweaking the code slightly). Such a well defined mode of working is highly tractable to event control and metadata capture.
Sumatra
Over the last year or so I have been using Sumatra to record simulation metadata. From my perspective, Sumatra’s most advantageous feature is it’s simple implementation as a command line tool. It consequently doesn’t make deep changes to my mode of working. In particular, launching a script requires one simple change at the command line from
$ python script.py param_file.json
to
$ smt run param_file.json
Please do take a look at this project and see if it fits with your own workflow, especially if you are an avid Python user. There is plenty of documentation and I have an IPython notebook demonstrating the use of Sumatra for a simple parallel problem. The notebook shows how to load the Sumatra records into a Pandas dataframe and then create custom dataframes mixing metadata and simulation output data. For Sumatra to remain (or become) a healthy open source project, it must reach a critical mass of users. In particular there are many issues on the tracker which will only be addressed with more users and contributors. I currently use Sumatra for all my simulation management and try to fix bugs and contribute back to the project whenever I can.
Cloud Service
I noticed recently that the main developer of Sumatra is now working on Sumatra-server. I am excited that this might form the basis for a client-server model for Sumatra and an eventual cloud service for simulation management. Such a service would lead to improved sharing of data, improved reproducible simulation results and then the eventual promised land of aggregation and analytics on metadata (and possibly output data) across disparate research projects.
To elucidate the value a cloud service for simulation management could provide, I would like to raise two of the ideas mentioned in C. Titus Brown’s blog post about reproducible research. These are:
-
“a declarative metadata standard that you can use to tell a Linux VM how to download your data”
-
“automated integration tests for papers”
These ideas are at the heart of making simulations truly reproducible. I believe that the client-server model of Sumatra can meet these two requirements. Regarding the first point: the tool that automatically captures the metadata and has the ability to rebuild an environment based on that metadata will become the de facto metadata standard. Regarding the second point: Sumatra already records the hash for output data files and has the functionality to rerun simulations and check that the hash matches thereby forming a coarse level regression test. Furthermore, integration of Sumatra with a continuous integration framework such as Buildbot would allow the testing process to be entirely automated whenever a code repository is updated.
What can NIST do to help?
I am part of the Data Storm Focus Group in the Materials Measurement Laboratory at the National Institute of Standards and Technology (NIST). The group aims to provide recommendations to upper management on the direction NIST needs to take in weathering the future data storm. In particular, the group will make recommendations on issues such as workflow management, reproducible research and data provenance issues. The group has also discussed physical infrastructure for scientific data though I have less interest in that area. From my perspective, some important actions NIST can take to improve scientific data management practices at NIST and in the wider scientific community include:
-
More active engagement with open source projects that are already answering the issues surrounding data capture and provenance.
-
Encourage NIST staff members to actively support the open source community, especially widely used projects that have primary developers external to NIST.
-
Take a less NIST-centered viewpoint about cloud services and open source projects. Acknowledge that open source projects are no longer associated with any particular academic institution.
-
Start thinking seriously about hosting cloud services for the general community including automated data provenance (this is low hanging fruit in a number of ways and the next frontier in scientific data management). In my opinion, the government (and by extension NIST) should host services for academic data management and workflow along the lines of Figshare, Wakari or Authorea.
-
Seek out open source projects addressing workflow and data provenance that are currently being used widely at NIST (such as IPython) and give grant money to the developers. There are multiple benefits to NIST in this approach including the possibility to influence these projects to meet NIST and the wider community’s needs without any large investment.
Conclusion
From my standpoint, we are on the cusp of a revolution in scientific data management, which will greatly improve scientific research and reproducible science and lead to analytics across disparate research projects. In particular to my own workflow, an important first step in this revolution is the development of effective cloud-based simulation record keeping and management. For me, it is great fun to be part of this revolution in some way by making contributions to projects such as Sumatra. Looking at the big picture, NIST really needs to be at the heart of supporting and providing cloud services and software tools for varying scientific communities in order to play a relevant part in the scientific data revolution.
Please see the slides from a talk I gave on Managing Numerical Simulations at the NIST Diffusion Workshop.
comments powered by Disqus